Core Observation
Helix 02 and pi0.7 are useful case studies because they expose two different modality requirements behind frontier physical-AI behavior.
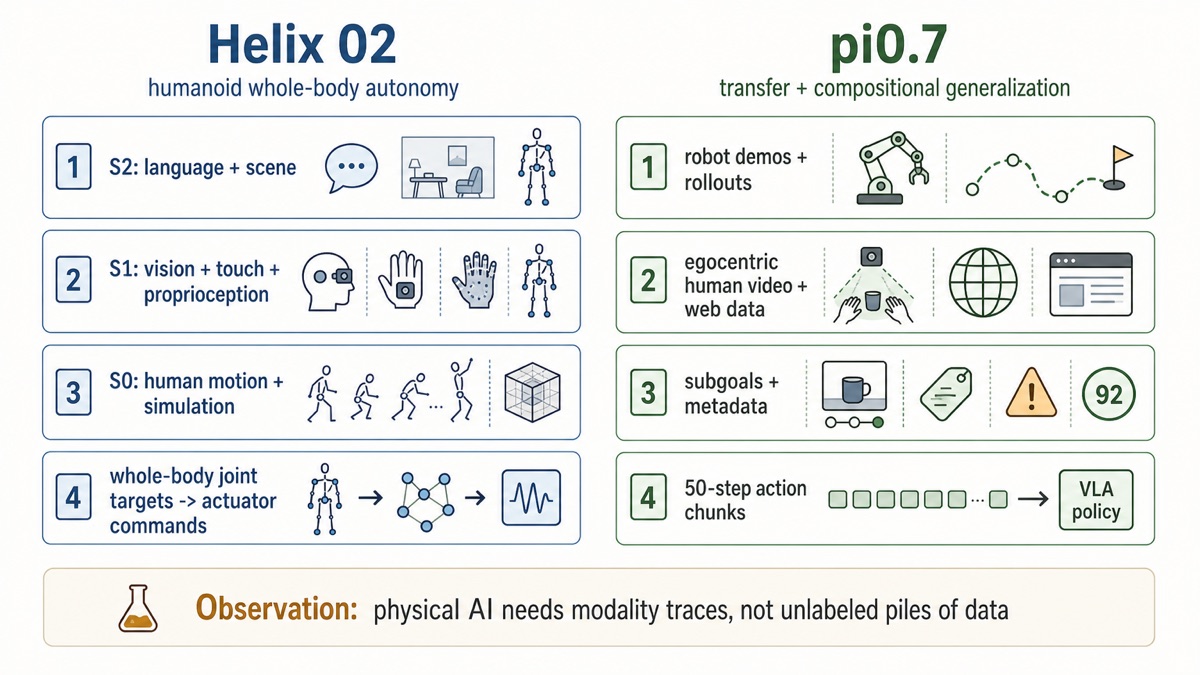
Figure's Helix 02 is a study in whole-body humanoid autonomy: language and scene reasoning, head and palm vision, fingertip tactile sensing, full-body proprioception, retargeted human motion, simulation, joint targets, and actuator-level control.
Physical Intelligence's pi0.7 is a study in transfer and compositional generalization: robot demonstrations, autonomous rollouts, failures, human interventions, open-source robot datasets, egocentric human video, web data, subtask instructions, generated visual subgoals, episode metadata, and control-mode labels.
The useful observation is not that physical AI needs a "data stack." It does. The useful observation is more concrete: autonomy and transfer depend on making the right physical signals legible to the policy.
Different Capability Targets, Different Modality Requirements
The comparison is useful because the two releases expose different capability targets. Helix 02 demonstrates long-horizon humanoid loco-manipulation. Figure reports a 4-minute autonomous dishwasher task with 61 loco-manipulation actions, no resets, and no human intervention [1].
pi0.7 demonstrates a different capability profile: out-of-the-box dexterity, instruction following, cross-embodiment transfer, and composition of skills in new ways [2]. The central question is whether a single generalist policy can use heterogeneous experience without averaging it into mediocre behavior.
That difference is why the modalities matter. Helix 02 makes body-level control signals visible. pi0.7 makes heterogeneous data-context signals visible.
Helix 02: Whole-Body Autonomy Requires Body Signals
Figure describes Helix 02 as a unified whole-body loco-manipulation VLA. The public architecture is split into three layers, each operating at a different timescale [1].
| Layer | Role | Public training evidence | Modalities | Policy or control role |
|---|---|---|---|---|
| System 2 | Slow semantic reasoning: scene understanding, language, and behavior sequencing. | The release describes the layer's semantic role, but does not disclose a separate S2 training corpus or dataset size. | Scene and language inputs; semantic latent goals. | Produces semantic latents that S1 interprets into motor commands. |
| System 1 | Fast visuomotor policy. | The release discloses S1 inputs and 200 Hz joint-target output, but not a separate S1 training corpus or dataset size. | Head cameras, palm cameras, fingertip tactile sensors, full-body proprioception. | Produces full-body joint targets at 200 Hz. |
| System 0 | Whole-body controller and embodiment prior. | Over 1,000 hours of joint-level retargeted human motion data; sim-to-real reinforcement learning across more than 200,000 parallel simulated environments. | Full-body joint state and base motion. | 10M-parameter neural network that outputs joint-level actuator commands at 1 kHz. |
The cleanest human-embodiment data point is System 0. Figure says S0 "learns to track human motion directly from a large and diverse corpus of movement data" and lists the training data as "over 1,000 hours of joint-level retargeted human motion data" [1].
The clearest manipulation-data point is System 1's sensor set. Figure says S1 takes head cameras, palm cameras, fingertip tactile sensors, and full-body proprioception as inputs and outputs complete joint-level control for the whole robot [1].
This is a body-level signal chain: semantic goals, whole-body perception, tactile/contact signals, proprioception, human-motion priors, simulation, joint targets, and high-frequency actuation.
pi0.7: Transfer Requires Contextualized Heterogeneous Data
Physical Intelligence describes pi0.7 as a 5B-parameter VLA with a 4B VLM backbone, a MEM-style video history encoder, and an 860M-parameter flow-matching action expert [2]. The action expert processes 50 action tokens, representing a 50-step action chunk; in experiments, pi0.7 executes 15 or 25 steps from each chunk before replanning.
The important empirical point is the data/context recipe. pi0.7 is trained with diverse prompts containing task descriptions, detailed language, generated subgoal images, and episode metadata [2]. The model is not only given more data. It is given context about what each episode means.
| Component | Publicly stated role | Modalities or data |
|---|---|---|
| Training data | Broad robot and non-robot mixture. | Robot demonstrations across many platforms; autonomous policy-evaluation data; failures; human interventions inside rollouts; open-source robot datasets; egocentric human video; auxiliary non-robot web data. |
| Observation stream | Robot state and recent visual history. | Up to four camera views, up to six history frames per view, and proprioceptive state. |
| Prompt context | Makes heterogeneous data steerable. | Task language, subtask instructions, subgoal images, speed metadata, quality score, mistake labels, and control mode. |
| World model | Generates visual subgoals for the policy. | Initialized from BAGEL, a 14B image generation/editing model with web-scale pretraining; augmented with web data, egocentric human videos, and other video data. |
| Action policy | Converts observations and context into actions. | 5B VLA with 860M flow-matching action expert; processes 50 action tokens as a 50-step action chunk; executes 15 or 25 steps from the chunk in experiments; supports joint and end-effector control modes. |
The paper's strongest warning is that diversity alone is not enough: "using such data naively does not lead to success" [2]. It explains why. When examples differ in both strategy and task performance, a naive training process can average together different modes and produce suboptimal behavior.
In pi0.7, diversity appears valuable only when paired with legibility. The model needs labels, subgoals, metadata, and control-mode context so that failures, slow successes, clean demos, human interventions, and autonomous rollouts do not collapse into one ambiguous behavior distribution.
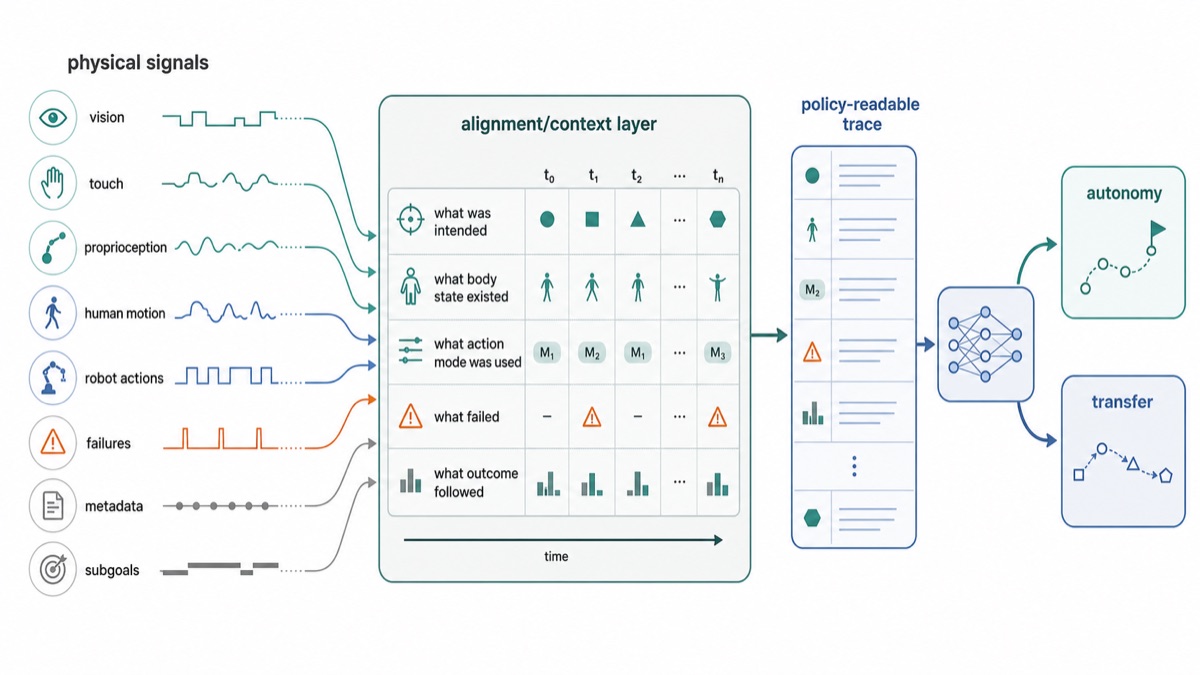
Data Modality Stack Trace
| Signal | Helix 02 evidence | pi0.7 evidence | What the signal makes legible |
|---|---|---|---|
| Language and task semantics | S2 interprets scenes, understands language, and sequences behaviors [1]. | Task language and subtask instructions are prompt components [2]. | Intent, task decomposition, next semantic step. |
| External vision | Head cameras feed S1 [1]. | Up to four camera views with history frames feed the model [2]. | Scene state, object state, spatial context. |
| Local or in-hand vision | Palm cameras provide in-hand feedback when objects are occluded from the head camera [1]. | Wrist views and generated subgoal images specify arm/gripper outcomes [2]. | Occluded manipulation state and near-future target state. |
| Touch and contact | Fingertip tactile sensors detect forces as small as 3 grams and enable force-modulated grasping [1]. | Tactile is not a central public modality in pi0.7. | Contact, grip quality, force-sensitive manipulation. |
| Proprioception | Full-body proprioception feeds S1; S0 consumes full-body joint state and base motion [1]. | Proprioceptive state is embedded into the VLA backbone [2]. | Body state, configuration, action grounding. |
| Human motion or human video | S0 trains on over 1,000 hours of joint-level retargeted human motion data [1]. | Training includes egocentric human video data; world-model training is augmented with egocentric human videos [2]. | Human behavior priors, motion priors, task demonstrations outside robot-only data. |
| Robot demonstrations | The Helix 02 release does not disclose whether robot demonstration datasets trained S1 or S2. | Demonstration data spans many robot platforms and environments [2]. | Direct observation-action grounding. |
| Autonomous rollouts | Helix 02 demonstrates autonomous execution; the release does not disclose whether autonomous rollout data was used for training. | Training includes autonomous policy-evaluation data, including failures [2]. | Recovery states, off-distribution states, performance variation. |
| Human interventions | No human-intervention training signal is disclosed for Helix 02 in the release. | Training includes human interventions within policy rollouts [2]. | Correction traces and recovery supervision. |
| Simulation | S0 uses sim-to-real RL across more than 200,000 parallel environments [1]. | Simulation is not the central public modality in the pi0.7 paper sections reviewed. | Robust low-level control and transfer to real robots. |
| Metadata | Metadata is not described as a Helix 02 training or control modality in the release. | Speed, quality, mistake labels, and control-mode labels are prompt context [2]. | Strategy, quality, failure, and action-space disambiguation. |
| Generated subgoals | No generated-subgoal mechanism is described for Helix 02 in the release. | A BAGEL-initialized world model generates visual subgoals [2]. | Visual specification of the desired near-future state. |
What Diversity Means Here
Diversity is not a vague positive word in the pi0.7 paper. It has a specific technical burden. The paper says the model uses data from many robots, diverse strategies, suboptimal autonomous execution, failures, human videos, and general multimodal internet data [2]. It then warns that naive use of such data does not work because the examples differ in strategy and performance.
More varied data is useful only if the downstream system can tell the difference between:
- a fast success and a slow success,
- a clean demonstration and a mistake-heavy episode,
- a human intervention and autonomous behavior,
- a task instruction and a subtask instruction,
- a desired visual state and the current visual state,
- joint-level control and end-effector control.
Helix 02 shows a complementary version of diversity. S0 does not train on one hand-coded gait or a set of isolated controllers. Figure says it learns from a large and diverse corpus of retargeted human movement, then uses simulation and domain randomization to transfer to robots [1].
The Takeaway
Helix 02 and pi0.7 expose different modality requirements behind frontier physical-AI behavior.
Helix 02 shows the modality requirements for long-horizon humanoid autonomy: language, scene understanding, head vision, in-hand vision, touch, proprioception, retargeted human motion, simulation, full-body joint targets, and actuator-level control.
pi0.7 shows the modality requirements for transfer and compositional generalization: robot demonstrations, egocentric human video, autonomous rollouts, failures, human interventions, web/non-robot data, subtask language, generated visual subgoals, metadata, and explicit control-mode labels.
The empirical lesson is not that one data source wins. It is that the policy needs a trace: what was seen, what was intended, what the body state was, what action mode was used, what quality level the episode had, what contact occurred, what failed, and what outcome followed.
References
-
[1]
Figure, "Introducing Helix 02: Full-Body Autonomy," 2026. figure.ai/news/helix-02
-
[2]
Physical Intelligence, "pi0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities," 2026. physicalintelligence.company/download/pi07.pdf