Physical AI is not one race.
It is a set of competing compounding loops.
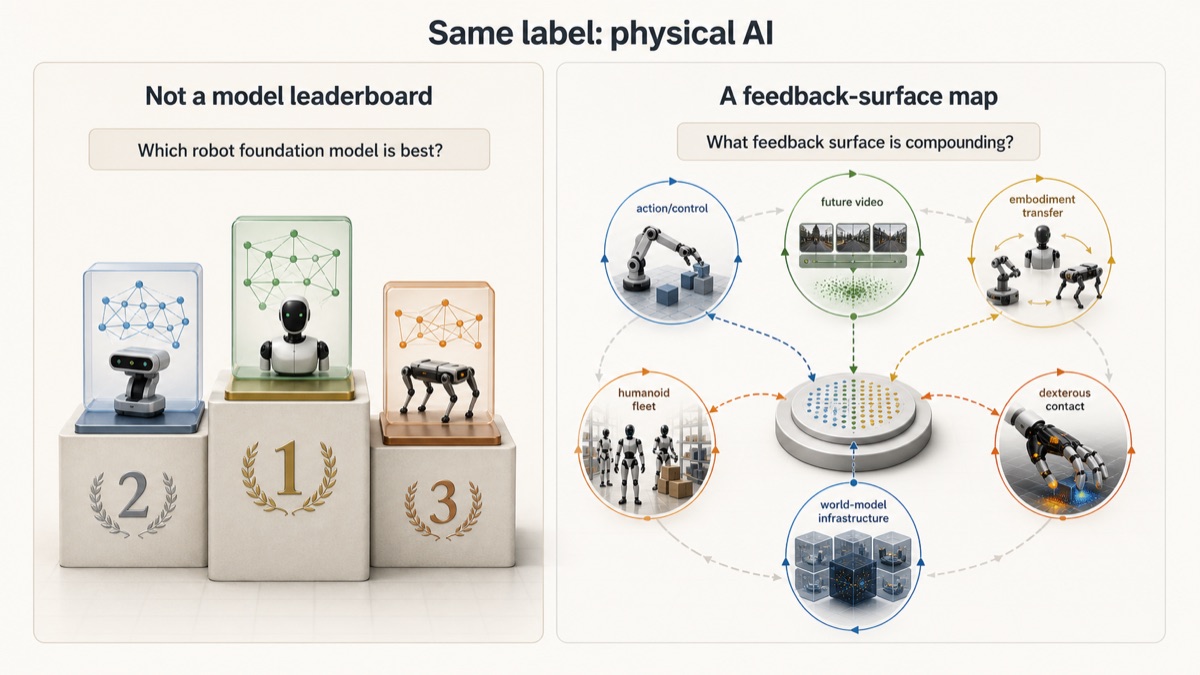
That is the central split: physical AI is becoming a contest between compounding feedback surfaces, not a single foundation-model race.
“Data flywheel” is one possible moat, but it is not the only one. The sharper question is which substrate a system is trying to make compound: a model-centered action policy, a whole-system deployment loop, a dexterous-contact stack, or shared physical-AI infrastructure.
This is not a claim that one lab has already won. It is a map of distinct feedback systems. Each system can look strongest if its loop captures the constraint customers encounter first in deployment.
Compounding Feedback Surfaces
The useful comparison separates the substrate, the feedback surface that compounds with use, and the scarce skill evidence that each system tries to capture.
Model-centered action policy
World-conditioned action-model substratePhysical Intelligence pi0.7 makes heterogeneous traces usable through prompts, metadata, control labels, memory, and visual subgoals.
Structured task traces: language, substeps, strategy, speed, quality, control mode, visual goal, and action chunk.
Whole-system deployment loop
Shared brain, body, deployment, and data-loop substrateRhoda, Skild, and Figure all need systems where deployed behavior, embodiment, failures, fleet operations, and customer tasks turn into the next update.
Future-video targets, robot trajectories, proprioception, inverse dynamics, morphology, action spaces, fleet telemetry, service events, and customer failures.
Dexterous-contact stack
Manipulation substrate where contact is scarceGenesis and RLWRLD compound through hand capture, contact-rich rollouts, simulation/evaluation, post-training, and recovery loops.
Glove data, hand state, tactile/contact, ego and third-person video, torque, future contact states, inverse-dynamics labels, DAgger recovery, and evaluation traces.
Infrastructure layer
Shared physical-AI tooling substrateNVIDIA Cosmos compounds as the reusable layer for generation, transfer, reasoning, curation, search, evaluation, and post-training around physical-AI systems.
Generated worlds anchored to real data, synthetic scenarios, curated video, retrieved edge cases, generated-output scores, and post-training traces.
World-Conditioned Action-Model Substrate: Physical Intelligence
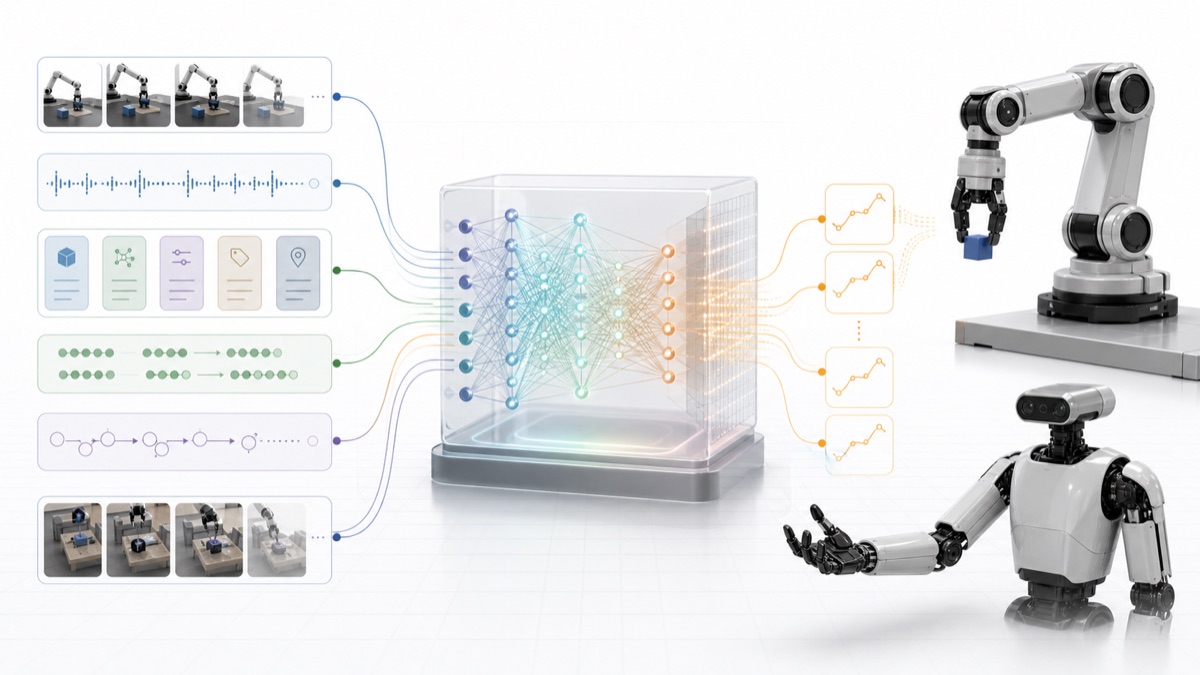
Physical Intelligence describes pi0.7 as a steerable generalist robot model trained with diverse multimodal prompts: language, metadata, control modalities, and visual subgoals. It also says test-time prompts can include a desired strategy and synthetically generated visual subgoals from a lightweight world model.
A thin reading would treat pi0.7 as a wider prompt surface. The mechanism is broader: pi0.7 uses visual subgoals to define spatial layouts, and those subgoal images can be generated at test time by a world model. The diagram also places a high-level policy and a world model upstream of the VLA: task instruction becomes subtask instruction and subgoal; the VLA then acts from observation memory, prompt, and action expert.
The important shift is that the policy is no longer just:
image + instruction -> actionIt is becoming closer to:
observation history
+ task language
+ subtask language
+ strategy
+ speed / quality metadata
+ control mode
+ visual subgoal
-> action chunksThat changes the data requirement. If a policy consumes strategy, speed, quality, control modality, and visual subgoals, then the data engine has to produce those fields. If visual subgoals are generated by a world model, the data engine also needs enough state, language, and outcome structure for that world model to produce useful intermediate targets. These are not optional labels. They become part of the action-selection substrate.
Whole-System Deployment Substrate: Rhoda, Skild, And Figure

Rhoda, Skild, and Figure are different technical bets, but they share a primary compounding shape. Each is trying to make a whole deployed system improve through the coupling between intelligence, embodiment, customer task, failure, and data capture.
The differences are where the loop enters the system: Rhoda enters through future-video policy, Skild through one brain across embodiments, and Figure through humanoid autonomy plus fleet operations.
Rhoda: Future-Video Policy
Rhoda’s Direct Video-Action model makes a different but related bet. Rhoda’s March 2026 page says DVA reformulates robot policies as video generation and defines DVA as a robot policy that translates predictions from a pre-trained causal video model into actions in a real-time closed loop, with the video model directly responsible for decision-making. A causal video model predicts future video conditioned on long robot-video context, proprioception, and language or other conditioning signals. An inverse dynamics model then translates the predicted future into robot actions.
The policy target changes from “next action” to “desired future.”
That is a meaningful frontier. If it works, generated video is more than synthetic data for pretraining. It becomes the representation through which the robot decides what to do.
The deployment-adaptation read follows from the same DVA framing. A causal video model starts from broad video priors, then robot-video context and proprioception steer the generated future before inverse dynamics turns that future into action.
Rhoda is a customer-deployment adaptation loop whose technical mechanism is future-video policy. The scarce substrate is not only robot video. It is web-video physical priors plus the in-domain robot trajectories, proprioception, inverse-dynamics labels, long-context observations, and customer-site edge cases needed to adapt the video-policy model to the next task or site.
Skild: Embodiment-Agnostic Robot Brain And Partner Deployment
Skild is the embodiment-transfer version of the deployment data-loop bet.
Skild’s public bet is broader than a single body form. It is a robot brain meant to work across embodiments. In its March 2026 partner announcement, Skild describes Skild Brain as a unified foundation model for physical AI that can control multiple kinds of machines. The same page frames the system as omni-bodied intelligence and announces partnerships with ABB Robotics, Teradyne Robotics’ Universal Robots and MiR, NVIDIA, and Foxconn.
The January 2026 learning-by-watching page is the data-side version of the same argument. Skild says teleoperation alone does not solve the foundation-model data bottleneck, because teleoperation is limited in diversity and scale. Its alternative is observational learning from human videos, then mapping observed skills across robot embodiments. Skild also explicitly names the hard parts: videos are missing forces, torques, and tactile feedback, and human hands, industrial arms, quadrupeds, and other bodies do not share the same morphology. The same page says Skild can fine-tune new skills from videos alone plus a small amount of robot data, specifically <1 hr. The important public signal is the structure of the claim: broad observational learning, then small robot-data additions for new skills.
The April 2026 Zebra page adds the deployment layer. Skild says it acquired the robotics division of Zebra Technologies, formerly Fetch Robotics, to deploy its omni-bodied brain across warehouses and accelerate the data flywheel. The same page claims the model transfers across quadrupeds, humanoids, tabletop arms, and mobile manipulators without retraining from zero.
That makes Skild an embodiment-transfer and partner-deployment version of the same category. The loop is not generic “porting skills.” It is a shared brain gathering paired evidence across robot bodies and customer environments, then using that evidence to improve embodiment transfer. For this compounding loop, the scarce substrate is morphology, kinematics, action spaces, task context, robot data, failure/recovery traces, and customer-environment outcomes.
Figure: Humanoid Fleet Substrate
Figure is a whole-system example: the public loop ties autonomy, embodiment, manufacturing, fleet operations, and customer deployment into one substrate.
Helix 02 is the autonomy layer. Figure describes it as a unified whole-body loco-manipulation VLA: a single neural system that extends control from the upper body to the entire humanoid, including walking, manipulating, and balancing. The stack is hierarchical. System 2 handles goals, scenes, language, and behavior sequencing. System 1 turns perception into full-body joint targets at 200 Hz. System 0 executes at 1 kHz, handling balance, contact, and coordination.
The substrate is inseparable from the body. Helix 02 uses head cameras, palm cameras, fingertip tactile sensors, and full-body proprioception. Figure says System 0 is trained on over 1,000 hours of joint-level retargeted human motion data plus sim-to-real reinforcement learning, with simulation across more than 200,000 parallel environments. The Figure 03 body supplies the tactile and palm-camera sensing that makes the Helix 02 manipulation examples possible.
The fleet layer is the compounding surface. In its April 2026 production-ramp page, Figure says it delivered more than 350 third-generation humanoids and increased production from one Figure 03 per day to one per hour. The same page says a larger fleet generates more data for Helix, exposes long-tail failures, feeds field-service and diagnostic systems, and supports fleet-wide behavior updates.
The customer layer is starting to appear publicly. In May 2026, Figure announced a Catalyst Brands agreement to deploy humanoids into a distribution and logistics network. That makes the Figure loop empirical: body production creates fleet hours; fleet hours expose failures and operating data; operating data feeds autonomy, reliability, and deployment playbooks.
Figure is best read as a coupled humanoid fleet system. Helix supplies the autonomy layer, Figure 03 supplies the sensor and body layer, manufacturing sets fleet scale, and service plus customer deployments turn real operation into the next data loop.
Dexterous-Contact Substrate: Genesis And RLWRLD

Genesis and RLWRLD are pushing a different frontier: dexterous manipulation.
Genesis GENE-26.5 is framed as a robotic foundation model system rather than only a checkpoint. Its May 2026 page argues that manipulation requires sensors, actuators, control, data, and models to be designed together. Its data engine is explicit: glove data for high-fidelity hand motion and tactile signals, egocentric video for natural behavior and task diversity, third-person video for physical interaction coverage, robot controls, simulation, and evaluation.
Genesis is broader than a contact-data story. It also describes a robotics-native foundation model that absorbs language, vision, proprioception, tactile, and action, then models a joint distribution over trajectories using flow matching. In the source, control, generative simulation, state estimation, inverse dynamics, goal inference, rendering, and value estimation arise as conditional queries on that joint distribution. Genesis also uses “world models” for action-conditioned video-generation models that capture temporal and physical dynamics.
Contact is central, but the system is a joint modeling and evaluation stack for manipulation.
For manipulation, ordinary video can miss the important part. A hand folding cloth, extracting a pill, adjusting a syringe, singulating small parts, handling a wire, or aligning a soft object depends on finger pose, pressure, slip, grasp transition, force, compliance, and timing. A model that cannot observe contact has to infer it. A system that captures contact can train on it directly.
RLWRLD’s RLDX-1 points in the same direction from the robot-hand side. Its page describes a dexterity-first foundation model for robot hands, with a Multi-Stream Action Transformer where each modality gets its own stream and joint self-attention lets the streams interact.
The modality list is revealing:
- vision-language;
- proprioception;
- action;
- memory;
- tactile;
- torque;
- video context;
- long-horizon memory.
RLWRLD also describes a synthetic data pipeline: amplify seed real demos using video generation models such as Cosmos-Predict2, annotate generated videos with inverse dynamics, then filter for instruction following and physical plausibility. Its Physics Module gives tactile and torque their own streams and predicts future contact states alongside actions. Its post-training section adds DAgger for recovery and a learned progress estimator for RL. The benchmark gains are company-published, but the direction is clear.
Dexterous hands are not smaller humanoids. They have a different modality bill of materials.
A five-finger manipulation trace can need tactile and torque streams where a simpler gripper policy does not. It can also need generated trajectories, inverse-dynamics labels, future contact-state prediction, recovery data, and progress rewards. That makes dexterity a capture, hardware, protocol, generative-data, post-training, simulation, and evaluation problem at the same time.
Infrastructure Substrate: NVIDIA Cosmos
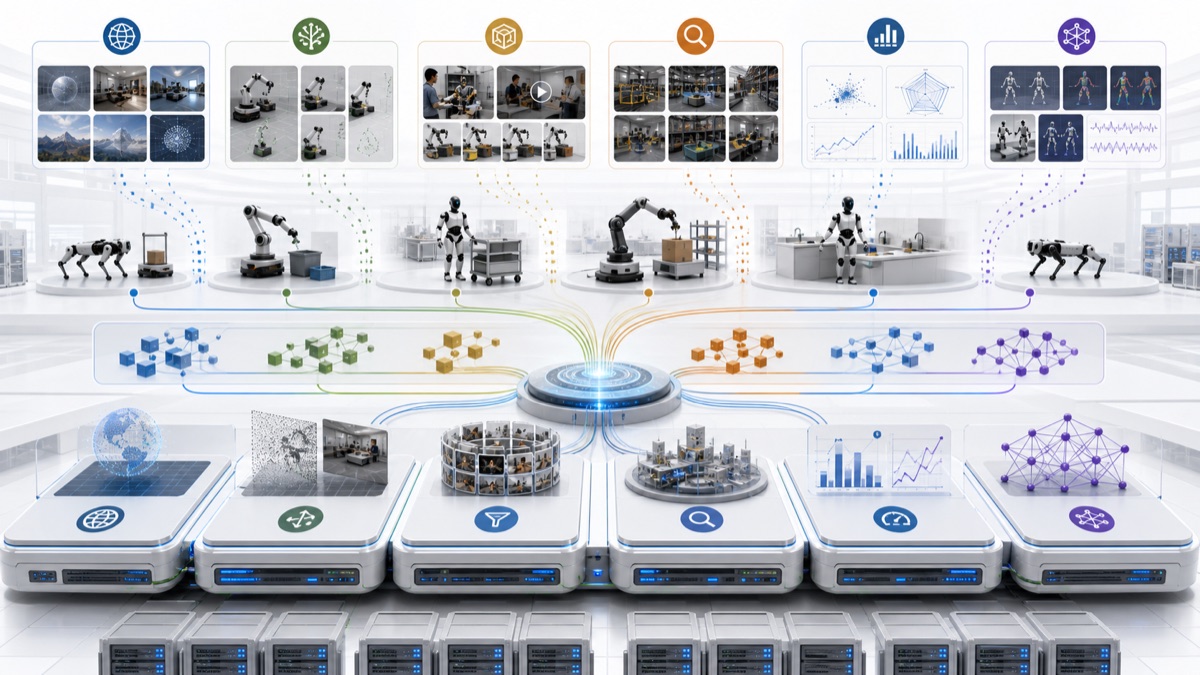
NVIDIA Cosmos is the infrastructure layer in this map: the shared substrate for world generation, simulation transfer, video curation, scenario search, evaluation, and post-training around physical-AI systems.
NVIDIA describes Cosmos as a platform for physical AI: world foundation models, video data processing libraries, video evaluation, post-training frameworks, and tools for building large-scale synthetic and real-data pipelines. Its compounding surface is the tooling layer that other teams can use around their own robot policies.
The public platform is organized around several surfaces:
- Cosmos Predict: world generation from text, image, or video;
- Cosmos Transfer: simulation-to-photoreal transformation;
- Cosmos Reason: vision-language reasoning for robots and vision AI agents;
- Cosmos Curator: filtering, annotation, and deduplication;
- Cosmos Dataset Search: scenario retrieval;
- Cosmos Evaluator: scoring generative video outputs.
This puts NVIDIA in a different position from PI, Rhoda, Skild, Figure, Genesis, and RLWRLD. Those systems compound through a specific policy, deployment, fleet, or dexterity loop. Cosmos compounds if the shared layer around those loops becomes reusable infrastructure: generate worlds, transform simulation, reason over scenes, curate video, retrieve scenarios, evaluate outputs, and post-train physical-AI models.
That infrastructure still depends on real tasks. Cosmos does not make real-world data less important; it increases the value of structured traces that can anchor generated worlds, filter scenarios, score rollouts, and close the loop after deployment.
What Compounds Next
Four substrates matter most next.
First, model-centered action policies become richer embodied control substrates. The model consumes more than images and instructions: metadata, strategy, memory, visual subgoals, generated futures, inverse-dynamics targets, and control modes become part of how the system chooses and executes action.
Second, whole-system deployment loops become the broadest operating category. Rhoda, Skild, and Figure differ in technical entry point, but each depends on a similar compounding shape: an intelligence layer, a body, real tasks, failures, fleet or customer evidence, and data loops that turn operation into the next system update.
Third, dexterous-contact stacks become a separate substrate inside whole-system development. Genesis and RLWRLD are not only collecting more robot data; they are trying to make tactile, torque, hand state, recovery, simulation/evaluation, and post-training compound around contact-rich manipulation.
Fourth, infrastructure becomes the reusable substrate around the field. World models can appear inside policies, inside future-video control, inside manipulation simulation, inside synthetic data generation, or as shared tooling. NVIDIA Cosmos is important in this map because it packages the surrounding infrastructure layer: generate, transfer, curate, search, evaluate, and post-train.
Deployment feedback is the unifying test. The next important dataset is not only teleoperation, internet video, or simulation. It is what happens when robots fail, recover, repeat, and improve in customer environments.
The synthesis is simple: physical AI is no longer one model race. It is splitting by the substrate that compounds: model-centered action policies, whole-system deployment loops, dexterous-contact stacks, and shared infrastructure. The test for the next phase is which substrate reaches real tasks, captures the scarce skill evidence, and turns that evidence into the next system improvement.
References
-
[1]
Physical Intelligence, "pi0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities," 2026. physicalintelligence.company/blog/pi07
-
[2]
Rhoda AI, "Direct Video-Action," Rhoda AI Research, March 2026. rhoda.ai/research/direct-video-action
-
[3]
Skild AI, "The Reindustrial Revolution," March 2026. skild.ai/blogs/reindustrial-revolution
-
[4]
Skild AI, "Learning by Watching," January 2026. skild.ai/blogs/learning-by-watching
-
[5]
Skild AI, "Skild and Zebra," April 2026. skild.ai/blogs/skild-zebra
-
[6]
Figure, "Introducing Helix 02: Full-Body Autonomy," 2026. figure.ai/news/helix-02
-
[7]
Figure, "Ramping Figure 03 Production," April 2026. figure.ai/news/ramping-figure-03-production
-
[8]
Figure, "Figure Signs Agreement with Catalyst Brands," May 2026. figure.ai/news/figure-signs-agreement-with-catalyst-brands
-
[9]
Genesis AI, "GENE-26.5: Advancing Robotic Manipulation to Human Level," May 2026. genesis.ai/blog/gene-26-5-advancing-robotic-manipulation-to-human-level
-
[10]
RLWRLD, "RLDX-1," 2026. rlwrld.ai/en/rldx-1
-
[11]
NVIDIA, "Cosmos," developer platform page, 2026. developer.nvidia.com/cosmos